ICML 2026
1Courant Institute School of Mathematics, Computing, and Data Science, New York University
✉ Corresponding author: sw5973@nyu.edu
TL;DR — Training LLM‑GFlowNets collapses into a few short, near‑identical samples. RapTB propagates terminal reward to every prefix via absorbed‑suffix backups, and SubM refreshes the replay buffer with a submodular reward‑diversity‑length objective. Together they cure prefix collapse and length bias, yielding markedly more diverse, higher‑quality generations at scales up to 32B.
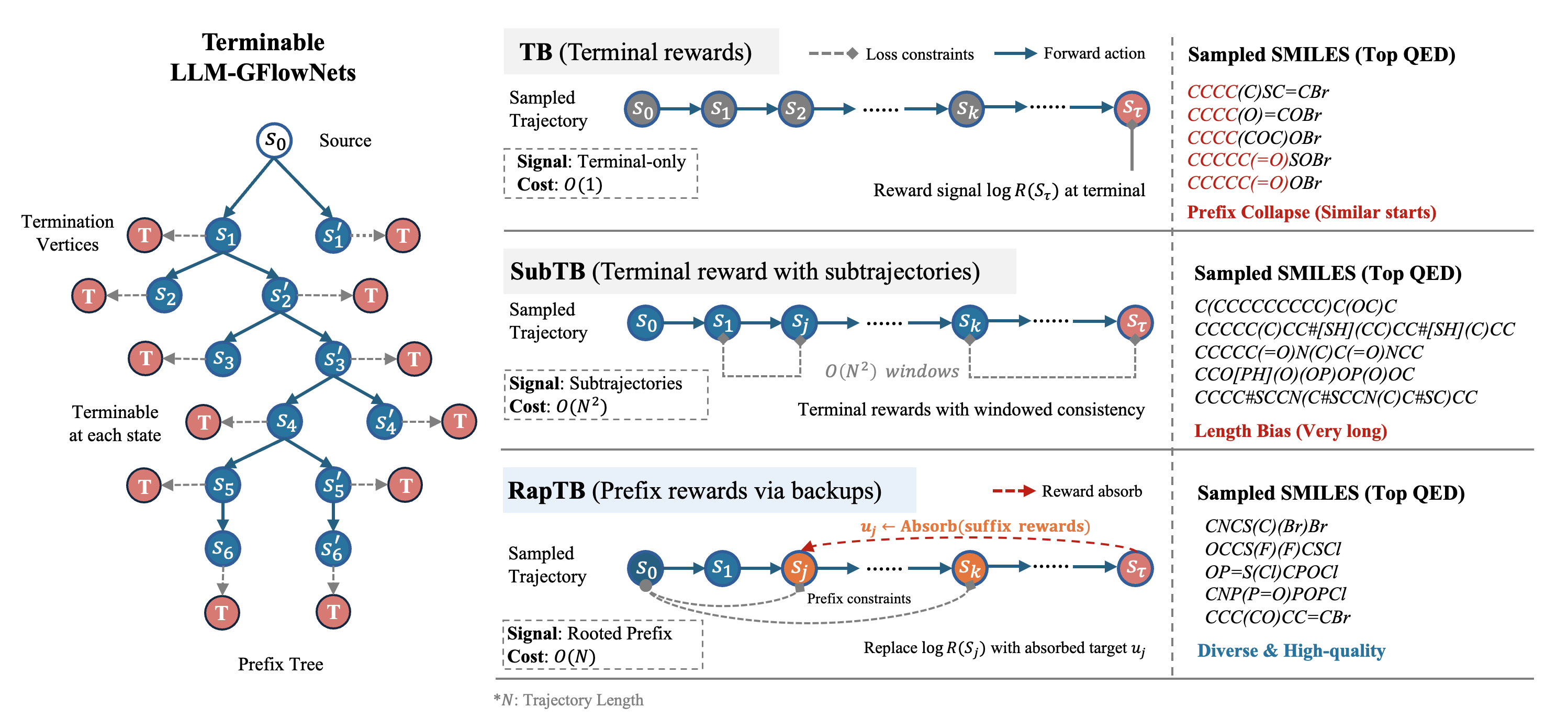
Generative Flow Networks (GFlowNets) enable fine‑tuning large language models to approximate reward‑proportional posteriors, but they remain prone to mode collapse, manifesting as prefix collapse and length bias. We attribute this to two factors: (i) weak credit assignment to early prefixes, and (ii) biased replay that induces a shifted, non‑representative training flow distribution. We propose Rooted absorbed prefix Trajectory Balance (RapTB), an objective that anchors subtrajectory supervision at the root and propagates terminal rewards to intermediate prefixes via absorbed suffix‑based backups, providing dense prefix‑level learning signals. To mitigate replay‑induced distribution shift, we further introduce SubM, a submodular replay refresh strategy that promotes both high reward and diversity. Empirically, on tasks such as molecule generation with LLMs using SMILES strings, RapTB combined with SubM consistently improves optimization performance and molecular diversity while preserving high validity.
LLM‑GFlowNets are supposed to spread probability mass across many high‑reward modes in proportion to reward. In practice, two coupled, reproducible failures appear:
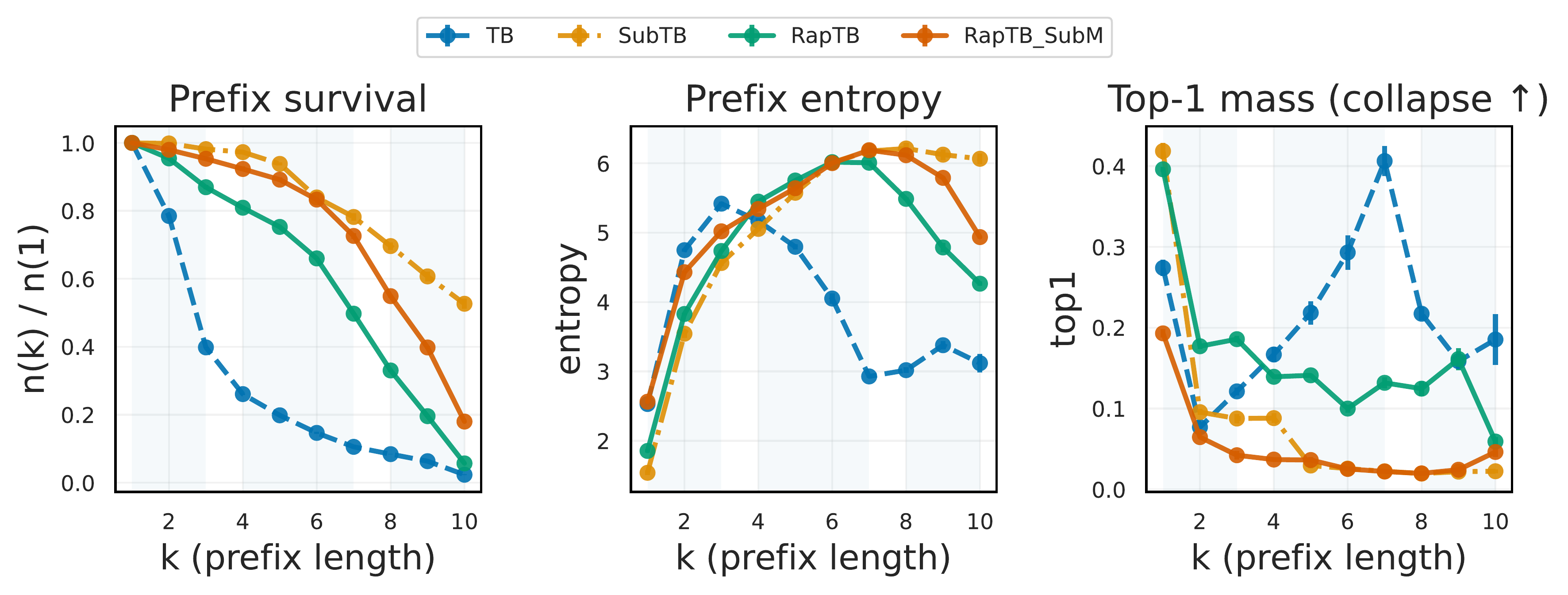
Early‑token entropy drops sharply; distinct terminals share near‑identical prefixes and only branch late. Root cause: terminal‑only rewards give high‑variance, ambiguous credit to intermediate steps.
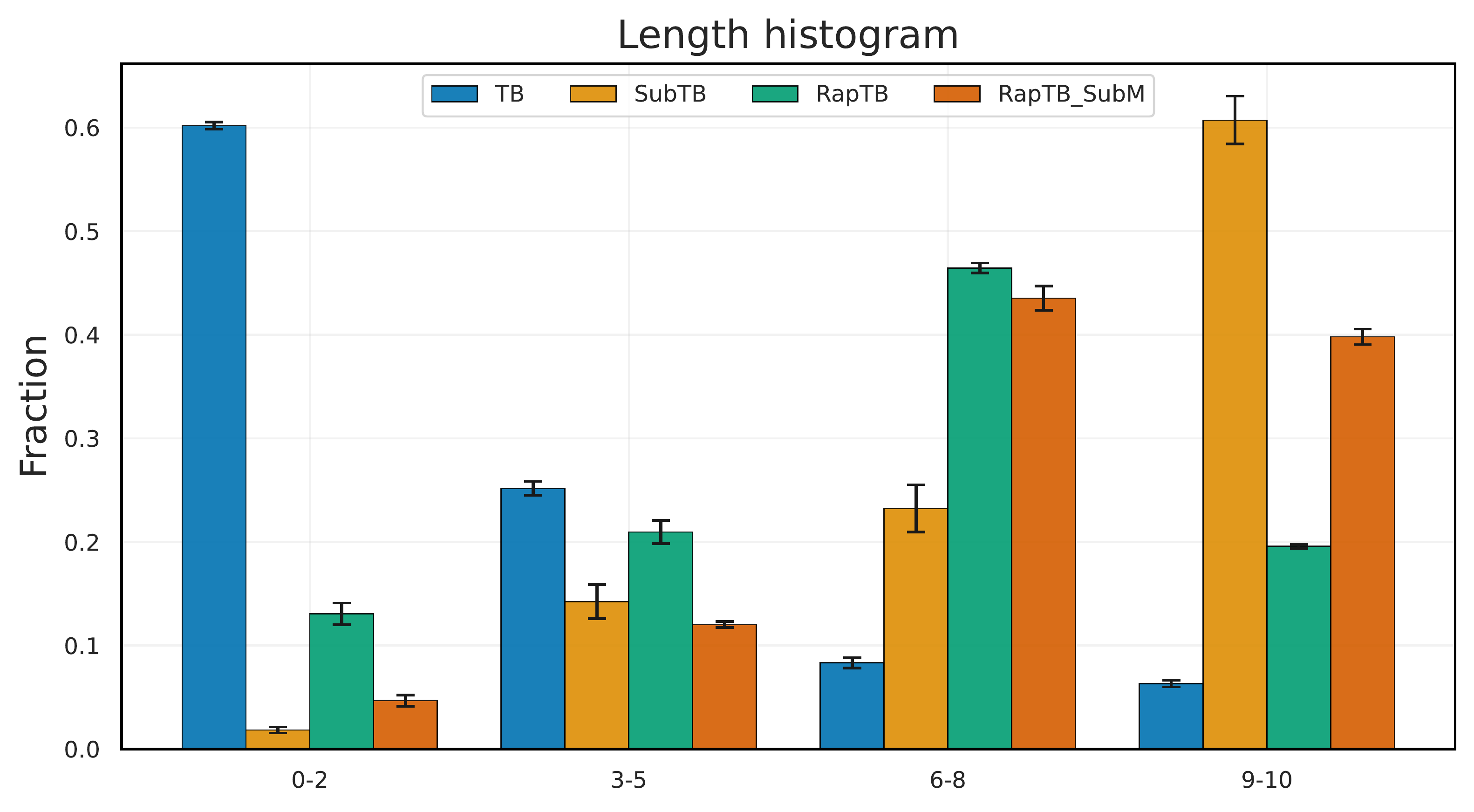
The policy systematically favors sequences that are too short (TB) or too long (SubTB). Root cause: biased replay reinforces a narrow subset, while overlapping window constraints drift the termination logits.
RapTB keeps terminal Trajectory Balance as the single exact balance constraint — the only condition whose optimum matches the reward‑proportional target — and adds a lightweight auxiliary term that delivers dense, low‑variance supervision at every prefix.
Instead of constraining all subtrajectories (as in SubTB), we only constrain those rooted at the source s0. Subtracting the root residual cancels the global constant log Zθ, giving a clean local consistency signal with no conflicting window boundaries:
We build a low‑variance target for each prefix by backing up rewards from the observed suffix — a max term (a lower bound on prefix credit) blended with a distance‑discounted soft‑max:
The auxiliary loss simply re‑computes the rooted residual against this absorbed target (with the termination head detached to prevent length drift), and the final objective keeps TB as the anchor:
Fixed‑point guarantee. The TB deviation of any RapTB minimizer is bounded by η·𝓛aux(θ*) and vanishes as η→0, so the auxiliary term regularizes without ever destroying the global TB anchor.
Reward‑prioritized replay creates rich‑get‑richer dynamics. SubM instead refreshes a fixed‑size buffer by greedily maximizing a monotone submodular objective over the union of the current buffer and the new batch — jointly rewarding quality, facility‑location diversity, and length coverage:
Greedy selection inherits a (1-1/e) near‑optimality guarantee; with cached similarities each refresh costs O(B|𝒢|) — about 10 ms of overhead per update.
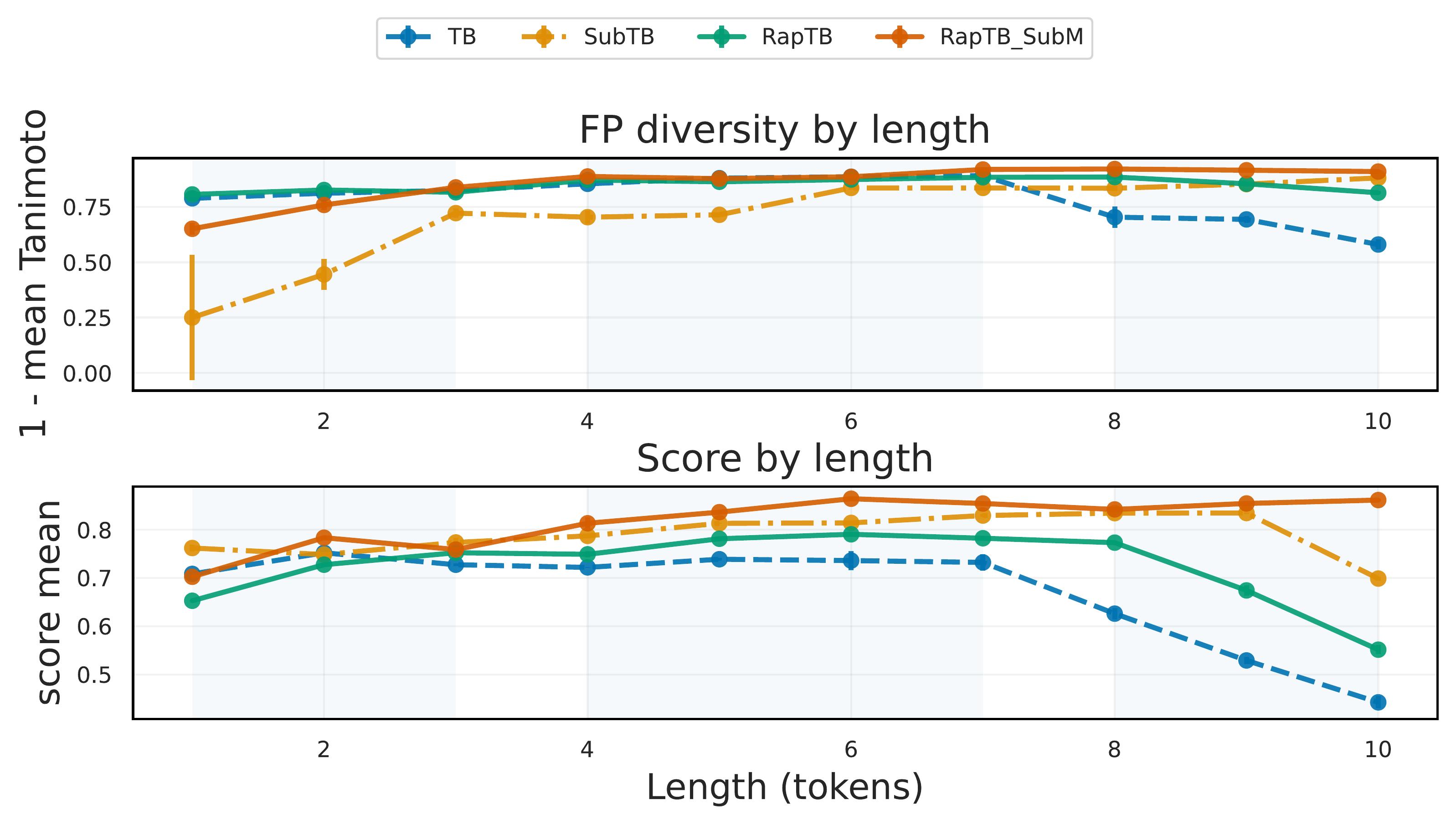
RL baselines maximize reward and collapse to a single mode (PPO entropy ≈ 0). Among GFlowNet objectives, TB is valid but short and low‑diversity; SubTB drifts and loses validity. RapTB + SubM wins the quality–diversity trade‑off while keeping validity high.
| Method | Acc ↑ | Score ↑ | Entropy ↑ | FPDiv ↑ | Len |
|---|---|---|---|---|---|
| PPO | 1.000 | 0.604 | ≈0 | — | — |
| GRPO | 0.997 | 0.661 | 0.98 | — | 10.0 |
| TB | 0.998 | 0.717 | 2.503 | 0.807 | 3.065 |
| SubTB | 0.328 | 0.755 | 2.127 | 0.836 | 8.354 |
| RapTB | 0.996 | 0.740 | 2.448 | 0.860 | 6.142 |
| RapTB + SubM | 0.988 | 0.844 | 2.726 | 0.898 | 7.435 |
Metrics on valid samples; Len is average token length. RapTB+SubM is best on Score, Entropy and FPDiv.
Generate an arithmetic expression evaluating to 24. Under standard replay, TB collapses to Unique✓≈5. RapTB recovers diversity at near‑perfect accuracy, and RapTB+SubM doubles normalized coverage (0.209 vs 0.100) over the strongest baseline. The enumerable solution set lets us verify lower KL/JS to the true reward distribution.
With a frozen reference LM as anchor, SubTB deviates catastrophically — saturating length (20.0) by suppressing stop logits (Δlog pterm≈−28). RapTB stays calibrated, and RapTB+SubM reaches BLEU‑4 33.2 at natural length (11.8) with the highest entropy.
Scaling & generality. Gains hold on AMP biological sequence generation and across Llama‑3.2 (1B/3B/8B) and Qwen3‑32B. SubTB's termination drift persists at every scale (Acc 0.31/0.39/0.80 at 3B/8B/32B), confirming the failure is structural, while RapTB+SubM gives the best quality–diversity trade‑off at all sizes.
@inproceedings{wang2026raptb,
title = {Rooted Absorbed Prefix Trajectory Balance with Submodular
Replay for {GFlowNet} Training},
author = {Wang, Xi and Lu, Wenbo and Wang, Shengjie},
booktitle = {Proceedings of the 43rd International Conference on
Machine Learning (ICML)},
year = {2026},
eprint = {2603.00454},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2603.00454}
}